Demystifying Java Bytecode: An Easy Intro
Introduction
Java bytecode serves as the crucial intermediate representation of Java source code, enabling the famous “write once, run anywhere” feature. Let’s explore the underlying language of the Java Virtual Machine (JVM).
Components of Java
Three essential components power the world of Java: the JDK, JRE, and JVM. The JDK (Java Development Kit) is the developer’s toolkit, incorporating the Java compiler and development tools. The JRE (Java Runtime Environment) is for end-users, ensuring Java applications run smoothly. The JVM, our focus here, is the runtime engine responsible for executing Java bytecode, rendering it independent of the underlying platform.

How bytecode is created?
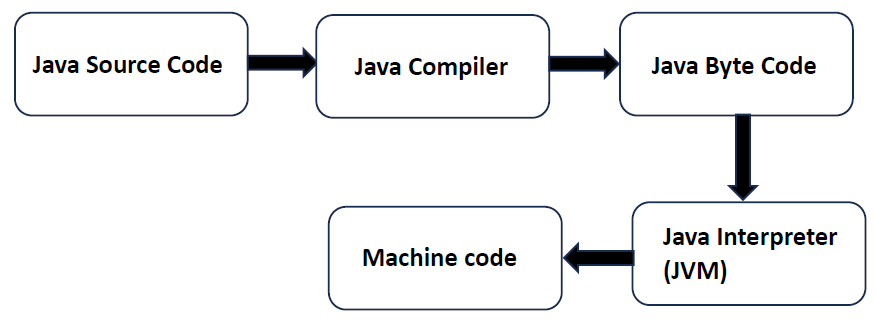
It all begins with Java source code and which is written in a human-readable format. The transformation process of creating a bytecode from the source code is handled by javac tool which is part of the Java Development Kit (JDK). If we compile the following code using javac Main.java command, javac transforms the code into a Main.class file which contains the bytecode. The process happens in several steps:
|
|
Syntax Checking
The javac compiler first checks the source code for syntax errors. If it finds any, it will abort and report as compilation error.
Bytecode Generation
Assuming there are no syntax errors, javac translates the Java source code into bytecode instructions. These instructions are platform-independent, meaning they can be executed on any device that has a Java Virtual Machine (JVM).
Digging Deeper into Bytecode
Disassembling bytecode
Java provided another command-line tool javap which is used for disassembling or decompiling Java bytecodes. It allows to view the bytecode instructions of compiled Java classes in a human-readable format. This tool is also part of the JDK. By running javap -c src/Main.class we can see the bytecode instructions:
|
|
Opcode
Opcode stands for operation codes, refer to the set of instructions used in bytecode to define the actions that the JVM should perform. These opcodes are fundamental building blocks that dictate how the JVM executes a Java program. Each opcode represents a specific operation, such as loading a value onto the stack, performing arithmetic operations, invoking methods or controlling program flow. All supported list of opcodes can be found in Oracle docs.
Opcode Breakdown
In our example bytecode above, we can see some instructions: iconst, istore, getstatic, iload, iadd and invokevirtual. Let’s explain:
iconstinstructs to load a constant on to the operand stack. The operand stack is a runtime data structure that is used to perform operations and computations. In our code, we defined two constants, 3 and 5 (int a = 3, b = 5;).istoreinstruction pops an integer from the operand stack and stores it in a local variable. If we look into the first four lines:
|
|
- Now line number 4,
getstaticinstruction is used to retrieve the value of a static field (class variable) from a class. Here we useSystem.out.println, if we look into the System source code,outis a static final field of the System class of typePrintStream.
|
|
It instructs to get the static Field java/lang/System.out of field data type Ljava/io/PrintStream. Here L in Ljava is a prefix used to represent a class type. java/io indicates the package where the PrintStream located at. The #2 references a constant pool entry that specifies this field.

- Next line number 7 & 8,
iloadinstructs to load a local variable onto the operand stack.iload_1loads the value from local variable slot 1 (byistore_1, which is3) onto the stack andiload_2loads the value from local variable slot 2 (byistore_2which is5) onto the stack.
|
|
iaddis an arithmetic addition instruction. This instruction adds the top two integers on the stack, which are 3 and 5. The result, 8, is left on the stack.
|
|
invokevirtualinvokes an instance method of an object, dispatching on the (virtual) type of the object. This is the normal method dispatch in the Java programming language. In line number 10, it invokes theprintlnmethod of thePrintStreamclass, which prints the integer value on the stack (8) to the standard output. The#3references a constant pool entry that specifies the method signature.
|
|
Why bytecode is slower than machine code?
Bytecode is typically slower than machine code because of the additional layer of interpretation and runtime checks. A machine code is a direct instruction to CPU, CPU can understand it and execute directly without any external help. On the other hand, bytecode is semi-compiled, its an intermediate state interpreted by the JVM, translated to machine code in rumtime.
JVM incorporates runtime checks for memory safety, security, and to enforce language rules (array bounds checking, null pointer checks etc). These checks are essential for security and stability but come at a cost in terms of execution speed. Machine code doesn’t typically include these checks, as it assumes the programmer has handled them at compile time.
While JIT compilation can optimize bytecode, it may not achieve the same level of optimization as a dedicated native compiler that generates machine code specific to the target platform. Native compilers can take advantage of low-level details and hardware-specific features, resulting in more efficient code.
Advantages of bytecode over machine code?
Although bytecode is slower than the machine code, Java uses bytecode for portability and security. Byte code is designed to be platform-independent, Since it’s an intermediate representation, it can be run on any platform that has a compatible JVM without modification.
JVM provides a layer of security. It enforces security checks, like access control and memory management, to prevent unauthorized or harmful actions. Bytecode doesn’t have direct access to system resources, which makes it harder for malicious code to compromise a system.
Bytecode allows for dynamic class loading at runtime. Classes can be loaded into the JVM on-demand, enabling features like reflection and dynamic class loading. Bytecode abstracts away many low-level details of memory management and hardware interaction, making Java easier to learn and program in than languages that compile directly to machine code.
Conclusion
In this article, we’ve taken a brief look at bytecode. For a deeper understanding of the intricate workings and structures of the JVM, you can explore the Java Virtual Machine Specification for detail underlying mechanism and structures of JVM.